ING disculpe la demora.
Definiremos algunas propriedades de los estimadores.
1) Parámetro. Verdadero valor de una caracterı́stica de interes, denominado por θ, que
raramente es conocido.
m uestra.
vies(θ̂) = E(θ ˆ θ) = E(θ̂) − θ
al azar de una población de gran tamaño tenderá a estar cerca de la media de la
población completa.
actitudes y la ansiedad hacia la estadística. Exceptuando dos instrumentos elaborados a partir
de escalas bipolares, a la manera del diferencial semántico de Osgood (Birenbaum y Eylath,
1994; Green, 1993), todos los instrumentos revisados son escalas tipo Likert. En lo que sigue
vamos a describir brevemente estos cuestionarios, poniendo un mayor énfasis en aquellos que
han sido usados más frecuentemente.
Intervalos de confianza
(
), es un intervalo de extremos aleatorios
que, con probabilidad
, contiene al parámetro en cuestión.
son
o
(la confianza es del
o
). En ocasiones también se emplea la terminología nivel de significación para el valor
.
. A partir de estos valores obtenemos un intervalo numérico. Por ejemplo, podríamos hablar de que, con una confianza del
por ciento, la proporción de voto al partido político “Unidas Ciudadanas” está entre el
y el
por ciento. O que, con una confianza del
por ciento, la estatura media está entre
y
.
Interpretación
datos diferentes, y valores diferentes (de la media muestral o de la proporción muestral).
.
garantiza que, si tomamos
muestras, el verdadero valor del parámetro estará dentro del intervalo en aproximadamente el
de los intervalos construidos.
personas (de nuevo si creen en los extraterrestres). De cada muestra podemos obtener una estimación puntual (calculada mediante la proporción en la muestra), y también un intervalo de confianza (que más adelante veremos cómo se calcula). Haremos este proceso
veces.
muestras definitivas
puntos porcentuales tienen un nivel del
de confianza, ¿cúantas personas se debe entrevistar para lograr esto?
% se detecte una diferencia clinicamente relevante con el nuevo tratamiento (si es que este es efectivo).
Tamaño de muestra para un error estándar determinado
, imaginemos que queremos una precisión (error estándar) de a lo más
, o
puntos >>>>>>> 1515a1256d14479ab9c3379e463a2bb4618be6ea porcentuales. Bajo muestreo aleatorio simple, para una muestra de tamaño
, el error estándar de la proporción
es
Sustituyendo nuestra expectativa
llegamos a que el error estándar sería
, de tal manera que si queremos
necesitamos
, en el caso de proporciones es fácil determinar el tamaño de muestra de manera conservadora pues basta con suponer
.
- Pruebas mas potentes.
- Más fácil de calcular y utilizar, ya que no requiere agrupación de datos.
- La estadística de prueba es independiente de la distribución de la frecuencia esperada. Sólo depende del tamaño de la muestra n.
H0: La distribución de frecuencia observada es consistente con la distribución de la frecuencia teórica (Buen ajuste).
H1: La distribución de frecuencia observada no es coherente con la distribución de la frecuencia teórica (Bad ajuste).
α = Nivel de significación de la prueba.
REPORT THIS AD
- Determinar la frecuencia observada acumulada y la frecuencia téorica acumulada, Po(x) y P(x).
- En cada caso, calcular: Dn = max | P(x) – Po(x) |
- Así, Dn es la máxima diferencia entre la función de distribución acumulada de la muestra y la función de distribución acumulada teórica escogida
- Fijar un nivel de probabilidad o de significancia α. Los valores de 0.05 y 0.01 son los más usuales.
- Determinar el valor crítico Dα en la tabla correspondiente.
- Aplica el criterio de decisión:
- Si el valor calculado Dn es menor que el Dα, se acepta la hipótesis nula (Ho) que establece que la serie de datos se ajusta a la distribución teórica escogida.
- Si el valor calculado Dn es mayor que el Dα, se rechaza la hipótesis nula (Ho) y se acepta la hipótesis alternativa (Ha) que establece que la serie de datos no se ajusta a la distribución teórica escogida.
porcentaje
|
nº de municipios
|
menos del 5%
|
18
|
entre el 5 y 10 %
|
14
|
entre 10 y 15%
|
13
|
entre 15 y 20%
|
16
|
entre 20 y 25 %
|
18
|
entre 25 y 30 %
|
17
|
entre 30 y 35 %
|
19
|
entre 35 y 40 %
|
24
|
entre 40 y 45 %
|
21
|
mas de 45%
|
18
|
grupos -variable
|
n0,i
| F0(xi) |
nt,i=n·P(xi)
|
F0(xi)
| |
menos del 5%
|
18
|
18/178=0,1011
|
17.8
|
17.8/178=0,1
|
0.0011
|
entre el 5y10 %
|
14
|
32/178=0,1798
|
17.8
|
35.6/178=02
|
0,0202
|
entre 10 y 15%
|
13
|
0,2584
|
17.8
|
0,3
|
0,0416
|
entre 15 y 20%
|
16
|
0,3427
|
17.8
|
0,4
|
0,0573
|
entre 20 y 25 %
|
18
|
0,4439
|
17.8
|
0,5
|
0,0561
|
entre 25 y 30 %
|
17
|
0,5393
|
17.8
|
0,6
|
0,0607 max
|
entre 30 y 35 %
|
19
|
0,6461
|
17.8
|
0,7
|
0,0539
|
entre 35 y 40 %
|
24
|
0,7809
|
17.8
|
0,8
|
0,0191
|
entre 40 y 45 %
|
21
|
0,8989
|
17.8
|
0,9
|
0,0011
|
mas de 45%
|
18
|
1
|
17.8
|
1
|
0
|
- Chi-Cuadrado: es recomendable para distribuciones discretas o continuas cuando existe gran cantidad de datos. Se recomienda trabajar con datos agrupados.
- Kolmogorov-Smirnov (K-S): es recomendable para distribuciones continuas y muestras de cualquier tamaño. No requiere hacer uso de datos agrupados.
El estadístico de Anderson-Darling
En este tema
¿Qué es el estadístico de Anderson-Darling?
Las hipótesis para la prueba de Anderson-Darling son:
- H0: Los datos siguen una distribución especificada
- H1: Los datos no siguen una distribución especificada
| Distribución | Anderson-Darling | Valor p |
|---|---|---|
| Exponencial | 9.599 | p < 0.003 |
| Normal | 0.641 | p < 0.089 |
| Weibull de 3 parámetros | 0.376 | p < 0.432 |

Exponencial

Normal

Weibull de 3 parámetros
Ejemplo de comparación de distribuciones
Mostrar el estadístico de Anderson-Darling en una gráfica de probabilidad normal
- Choose and
- Marque Incluir prueba de Anderson-Darling con gráfica normal. Haga clic en Aceptar. Minitab no muestra la prueba cuando hay menos de 3 grados de libertad para el error.
2) Estimativa. Valor numérico obtenido por el estimador, denominado de θ̂ en una
3) Viés y no viés. Un estimador es no in-sesgado si: E(θ̂) = θ, onde el viés es dado por:
Cuadrado médio del error (ECM). Es dado por:
ECM (θ̂) = E(θ̂ − θ)2 = V (θ̂) + (vies
1) Un estimador es consistente si: plim(θ̂) = θ ; y lim −→ ∞ECM (θ̂) = 0
2) Las leyes de los grandes números explican por qué el promedio o media de una muestra
4.1.1 Instrumentos de medición
El análisis de la literatura existente arroja un resultado de 17 instrumentos de medida de las
La estimación puntual aproxima mediante un número el valor de una característica poblacional o parámetro desconocido (la altura media de los españoles, la intención de voto a un partido en las próximas elecciones generales, el tiempo medio de ejecución de un algoritmo, el número de taxis…) pero no nos indica el error que se comete en dicha estimación.
Lo razonable, en la práctica, es adjuntar, junto a la estimación puntual del parámetro, un intervalo que mida el margen de error de la estimación. La construcción de dicho intervalo es el objetivo de la estimación por intervalos de confianza.
Un intervalo de confianza para un parámetro con un nivel de confianza
Los valores más habituales del nivel de confianza
En la estimación por intervalos de confianza partimos de una muestra
Igual que vimos antes con las encuestas de las estaturas, o de la proporción de gente que cree en los extraterrestres, con cada muestra obteníamos
De cada muestra también puede obtenerse un intervalo de confianza. Entonces, con cada muestra diferente, obtendremos un intervalo también diferente. A medida que aumenta la cantidad de intervalos que hemos construido, el porcentaje de intervalos que contienen el verdadero valor del parámetro se aproximará al
Así, por ejemplo, un intervalo de confianza al
Veamos un ejemplo mediante simulación. Vamos a simular que realizamos encuestas, en este caso preguntando a
Cuando se esta diseñando un estudio se determina la precisión en las inferencias que se desea, y esto (junto con algunos supuestos de la población) determina el tamaño de muestra que se tomará. Usualmente se fija uno de los siguientes dos objetivos:
- Se determina el error estándar de un parámetro o cantidad de interés (o de manera equivalente se fija la longitud máxima aceptable del intervalo de confianza que resultará). Por ejemplo, en encuestas electorales es típico reportar los resultados de esta encuesta más menos
- Se determina la probabilidad de que un estadístico determinado sea estadísticamente significativo. Por ejemplo, cuando se hacen ensayos clínicos se determina un tamaño de muestra para que con probabilidad de
En muchos casos existen fórmulas para calcular tamaños de muestra de tal manera que se cumplan los objetivos planteados, sin embargo, conforme se agrega complejidad al levantamiento de los datos (faltantes, levantamientos en varias etapas, …) o si nos alejamos de las estadísticas típicas, las fórmulas dejan de aplicar o se vuelven muy complejas, de manera que suele ser conveniente recurrir a simulación. Veremos dos ejemplos que se tomaron de Gelman and Hill (2007).
Supongamos que queremos estimar el porcentaje de la población que <<<<<<< HEAD apoya la pena de muerte. Sospechamos que la proporción es 60%, imaginemos que queremos un error estándar de a lo más 0.05, o 5 puntos ======= apoya la pena de muerte. Sospechamos que la proporción es
Etapas de una investigación
La Estadística nos permite realizar inferencias y sacar conclusiones a partir de los datos.
Extrayendo la información contenida en los datos, podremos comprender mejor las
situaciones que ellos representan.
Los métodos estadísticos abarcan todas las etapas de la investigación, desde el diseño
de la investigación hasta el análisis final de los datos.
Podemos distinguir tres grandes etapas:
1. Diseño: Planeamiento y desarrollo de las investigaciones
2. Descripción: Resumen y exploración de los datos
3. Inferencia: Predicciones y toma de decisiones sobre las características de una
población en base a la información recogida en una muestra de la población.
En la etapa de Diseño se define cómo se desarrollará la investigación con el fin de
responder las preguntas que le dieron origen. Un diseño bien realizado puede ahorrar
esfuerzos en etapas posteriores y puede redundar en un análisis posterior más sencillo.
Esta etapa es crucial, pues un estudio pobremente diseñado o con datos incorrectamente
recolectados o registrados puede ser incapaz de responder las preguntas que originaron
el estudio.
Una vez formulado el problema, en la etapa de Diseño se definirá, entre otras cosas, la
población objetivo, los tamaños de muestra, los mecanismos de selección de individuos,
los criterios de inclusión y exclusión de sujetos, los métodos de asignación de
tratamientos, las variables que se medirán y cómo se entrenará al equipo de trabajo para
el cumplimiento del protocolo.
Los métodos de Análisis Exploratorio o Estadística Descriptiva ayudan a comprender
la estructura de los datos, de manera de detectar tanto un patrón de comportamiento
general como apartamientos del mismo. Una forma de realizar ésto es mediante gráficos
de sencilla realización e interpretación. Otra forma de describir los datos es resumiendo
los datos en uno, dos o más números que caractericen al conjunto de datos con fidelidad.
Explorar los datos permitirá detectar datos erróneos o inesperados y nos ayudará a
decidir qué métodos estadísticos pueden ser empleados en etapas posteriores del análisis
de manera de obtener conclusiones válidas.
Finalmente, la Inferencia Estadística nos permite tanto hacer predicciones y
estimaciones como decidir entre dos hipótesis opuestas relativas a la población de la cual
provienen los datos (test de hipótesis).
La calidad de las estimaciones puede ser muy variada y están afectadas por errores. La
ventaja de los métodos estadísticos es que, aplicados sobre datos obtenidos a partir de
muestras aleatorias, permiten cuantificar el error que podemos cometer en una
estimación o calcular la probabilidad de cometer un error al tomar una decisión en un test
de hipótesis.
Para entender qué tipo de problemas consideraremos en Estadística tomemos, por
ejemplo, las siguientes mediciones de la proporción de la masa de la Tierra con respecto
a la Luna
130
Mariner II 81.3001
Mariner IV 81.3015
Mariner V 81.3006
Mariner VI 81.3011
Mariner VII 81.2997
Pioneer VI 81.3005
Pioneer VII 81.3021
En Probabilidad podríamos suponer que las posibles mediciones se distribuyen alrededor
del verdadero valor 81.3035 siguiendo una distribución determinada y nos
preguntaríamos
¿Cuál es la probabilidad de que se obtengan 7 mediciones menores que el verdadero
valor de la media?
En Estadística, a partir de los 7 observaciones nos preguntaríamos:
¿Son consistentes los datos con la hipótesis de que el verdadero valor del cociente es
81.3035?
¿Cuán confiable es decir que el verdadero valor está en el intervalo (81.2998, 81.3018)?
Las técnicas del análisis exploratorio nos ayudan a organizar la información que proveen
los datos, de manera de detectar algún patrón de comportamiento así como también
apartamientos importantes al modelo subyacente. Nos guían a la estructura subyacente
en los datos de manera rápida y simple.
Estadística Descriptiva
Examinaremos los datos en forma descriptiva con el fin de:
• Organizar la información
• Sintetizar la información
• Ver sus características más relevantes
• Presentar la información
Factores necesarios para un buen análisis estadístico:
• Diseño del Experimento o Investigación
• Calidad de los Datos
Definimos:
Población: conjunto total de los sujetos o unidades de análisis de interés en el estudio
Muestra: cualquier subconjunto de sujetos o unidades de análisis de la población en
estudio.
131
Organizaremos la información que proveen los datos
De manera de detectar algún patrón de comportamiento,
así como también apartamientos importantes
al modelo subyacente.
Asimismo, definimos:
- UNIDAD DE ANÁLISIS O DE OBSERVACIÓN: al objeto bajo estudio. Puede ser una
persona, una familia, un país, una institución o en general, cualquier objeto.
- VARIABLE: a cualquier característica de la unidad de observación que interese
registrar y que en el momento de ser registrada puede ser transformada en un
número.
- VALOR de una variable, DATO u OBSERVACIÓN o MEDICIÓN: al número que
describe a la característica de interés en una unidad de observación particular.
- CASO o REGISTRO: al conjunto de mediciones realizadas sobre una unidad de
observación.
En estadística, la prueba de Kolmogórov-Smirnov (también prueba K-S) es una prueba no paramétrica que determina la bondad de ajuste de dos distribuciones de probabilidad entre sí.
La prueba de Kolmogorov-Smirnov se utiliza para probar la bondad del ajuste de una distribución de frecuencia teórica, es decir, si existe una diferencia significativa entre la distribución de la frecuencia observada y la distribución de frecuencia teórica (esperada).
En un post anterior cubrimos el metodo Chi-Cuadrado. La prueba de K-S es similar a lo que hace la prueba de Chi-Cuadrado, pero la prueba K-S tiene varias ventajas:
LA HIPÓTESIS:
Este procedimiento es un test no paramétrico que permite establecer si dos muestras se ajustan al mismo modelo probabilístico (Varas y Bois, 1998).
Es un test válido para distribuciones continuas y sirve tanto para muestras grandes como para muestras pequeñas (Pizarro et al, 1986).
Así mismo, Pizarro (1988), hace referencia a que, como parte de la aplicación de este test, es necesario determinar la frecuencia observada acumulada y la frecuencia teórica acumulada; una vez determinadas ambas frecuencias, se obtiene el máximo de las diferencias entre ambas.
El estadístico Kolmogorov-Smirnov, D, considera la desviación de la función de distribución de probabilidades de la muestra P(x) de la función de probabilidades teórica, escogida Po(x) tal que:
Dn = max | P(x) – Po(x) |
La prueba requiere que el valor Dn calculado con la expresión anterior sea menor que el valor tabulado Dα para un nivel de significancia (o nivel de probabilidad) requerido. El valor crítico Dα de la prueba se obtiene de la tabla mostrada, en función del nivel de significancia α y el tamaño de la muestra n.
Tabla de valores de Dα en función del nivel de significancia y del tamaño de la muestra:

El procedimiento a seguir en la aplicación práctica de la prueba de Kolmogorov-Smirnov es el siguiente:
EJEMPLO PRUEBA DE KOLMOGOROV SMIRNOV
Se ha realizado una muestra a 178 municipios al respecto del porcentaje de población activa dedicada a la venta de ordenadores resultando los siguientes valores :
Queremos contrastar que el porcentaje de municipios para cada grupo establecido se distribuye uniformemente con un nivel de significación del 5%.
Bajo la hipótesis nula cada grupo debiera de estar compuesto por el 10% de la población dado que existen diez grupos . Así podemos establecer la tabla
Siendo la máxima diferencia 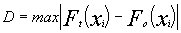 =0,0607 y por tanto el estadístico de K-S que compararemos con el establecido en la tabla que será para un nivel de significación de 5% y una muestra de 178 (ir a tabla K-S aqui)
=0,0607 y por tanto el estadístico de K-S que compararemos con el establecido en la tabla que será para un nivel de significación de 5% y una muestra de 178 (ir a tabla K-S aqui) 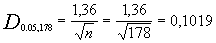 dado que el estadístico es menor (0,0607) que el valor de la tabla (0,1019) no rechazamos la hipótesis de comportamiento uniforme de los grupos establecidos al respecto de la población activa dedicada a la venta de ordenadores.
dado que el estadístico es menor (0,0607) que el valor de la tabla (0,1019) no rechazamos la hipótesis de comportamiento uniforme de los grupos establecidos al respecto de la población activa dedicada a la venta de ordenadores.
Para finalizar, ¿en que casos es recomendable cada estadístico?
- El estadístico Anderson-Darling mide qué tan bien siguen los datos una distribución específica. Para un conjunto de datos y distribución en particular, mientras mejor se ajuste la distribución a los datos, menor será este estadístico. Por ejemplo, usted puede utlizar el estadístico de Anderson-Darling para determinar si los datos cumplen el supuesto de normalidad para una prueba t.Utilice el valor p correspondiente (si está disponible) para probar si los datos provienen de la distribución elegida. Si el valor p es menor que un nivel de significancia elegido (por lo general 0.05 o 0.10), entonces rechace la hipótesis nula de que los datos provienen de esa distribución. Minitab no siempre muestra un valor p para la prueba de Anderson-Darling, porque este no existe matemáticamente para ciertos casos.También puede utilizar el estadístico de Anderson-Darling para comparar el ajuste de varias distribuciones con el fin de determinar cuál es la mejor. Sin embargo, para concluir que una distribución es la mejor, el estadístico de Anderson-Darling debe ser sustancialmente menor que los demás. Cuando los estadísticos están cercanos entre sí, se deben usar criterios adicionales, como las gráficas de probabilidad, para elegir entre ellos.
Estas gráficas de probabilidad son para los mismos datos. Tanto la distribución normal como la distribución de Weibull de 3 parámetros ofrecen un ajuste adecuado a los datos.
Minitab calcula el estadístico de Anderson-Darling usando la distancia al cuadrado ponderada entre la línea ajustada de la gráfica de probabilidad (con base en la distribución elegida y usando el método de estimación de máxima verosimilitud o las estimaciones de mínimos cuadrados) y la función de paso no paramétrica. El cálculo tiene mayor ponderación en las colas de la distribución.Para ver una leyenda que muestre el estadístico de la prueba de Anderson-Darling y el valor p cada vez que usted cree una gráfica de probabilidad normal de los residuos:
de prueba es:Puede demostrarse que sigue aproximadamente la distribución ji cuadrada conk – p – 1 grados de libertad,donde prepresenta el número de parámetros de ladistribución hipotética estimada por medio de estadísticas de muestra. Estaaproximación se mejora cuando naumenta. Rechazaríamos la hipótesis de que Xse ajusta a la distribución hipotética
No hay comentarios.:
Publicar un comentario