4.1. Lista de estimadores a obtener de la simulación.
Hasta ahora hemos estudiado cómo simular probabilidades de elección pero no
hemos estudiado las propiedades de los estimadores de los parámetros que se
basan en estas probabilidades simuladas. En los casos que hemos presentado,
simplemente hemos insertado las probabilidades simuladas en la función log-
verosimilitud y hemos maximizada dicha función, de la misma forma que lo
habríamos hecho si las probabilidades hubieran sido exactas. Este procedimiento
parece intuitivamente razonable. Sin embargo, no hemos mostrado realmente, al
menos hasta ahora, que el estimador resultante tenga propiedades deseables,
como consistencia, normalidad asintótica o eficiencia. Tampoco hemos explorado
la posibilidad de que otras formas de estimación puedan ser preferibles cuando
usamos simulación, en lugar de las probabilidades exactas. El propósito de este
capítulo es examinar varios métodos de estimación en el contexto de la simulación.
Derivaremos las propiedades de estos estimadores y mostraremos las condiciones
en las que cada estimador es consistente y asintóticamente equivalente al estimador
que obtendríamos si usásemos valores exactos en lugar de simulación. Estas
condiciones proporcionan una guía al investigador sobre cómo debe llevarse a cabo
la simulación para obtener estimadores con propiedades deseables. El análisis
también pone en evidencia las ventajas y limitaciones de cada forma de estimación,
facilitando así la elección del investigador entre los diferentes métodos.
Las técnicas de simulación en estadística, como son los métodos de Monte Carlo,
y los procedimientos de re muestreo conocidos como bootstrap, son de gran utilidad
cuando no tenemos expresiones cerradas para calcular medidas de incertidumbre
como son la desviación estándar de estimadores y los intervalos de confianza. Estos
métodos de simulación permiten obtener estimaciones con menores supuestos que
los métodos analíticos, a cambio de un trabajo computacional más intenso. La
disponibilidad creciente de los recursos computacionales, hacen de las técnicas de
simulación una herramienta de uso creciente. En este trabajo se discuten estas
técnicas de simulación, y se ilustran con ejemplos sencillos.
En el contexto estadístico, entendemos por simulación, la técnica de muestreo
estadístico controlado, que se utiliza conjuntamente con un modelo, para obtener
respuestas aproximadas a preguntas que surgen en problemas complejos de tipo
probabilístico. En metrología, el proceso de medición es de naturaleza probabilística
y los modelos de medición con frecuencia son complejos [1]. Estas dos
características del proceso de medición, complejidad y aleatoriedad, hacen del
análisis de datos de medición un área de oportunidad natural para los métodos de simulación
La variedad de problemas sociales y educativos, útiles y capaces de ser investigados,
guían el camino de la investigación hacia una gran diversidad y plasticidad de
metodologías y de técnicas adecuadas en la obtención de la información. De todos los
instrumentos probados, uno de los más usados universalmente por las Ciencias Sociales,
incluyendo la educación, es el cuestionario.
En términos generales, como todos sabemos, este instrumento consiste en aplicar a un
universo definido de individuos una serie de preguntas o ítems sobre un determinado
problema de investigación del que deseamos conocer algo. Las respuestas normalmente
son registradas por escrito por la persona consultada.
Los teóricos de la investigación sostienen a grandes rasgos que en Ciencias Sociales
existirían dos modalidades de cuestionarios: los que se refieren a la medición y
diagnóstico de la personalidad, utilizado normalmente en psicología, y los empleados
para recoger información en las investigaciones. En el caso de estos últimos, Delio del
Rincón240 recuerda los juicios de Ghigliona y Matalón241, cuando éstos señalan que los
cuestionarios tienen tres objetivos básicos:
• Estimar ciertas magnitudes absolutas como un censo de población; o magnitudes
relativas tales como la proporción de una tipología concreta en una población
estudiada.
• Describir una población o subpoblación: qué características tienen en un contexto
determinado.
• Contrastar hipótesis de acuerdo con las relaciones existentes entre dos o más
variables.
240 Delio Del Rincón [et al.]. Técnicas de investigación en Ciencias Sociales. Madrid:
Ediciones Dykinson, 1995.
241 Rodolphe Ghiglione; Benjamin Matalon. Las encuestas sociológicas: teorías y práctica.
México: Ediciones Trillas, 1989.
DESCRIPCIÓN DE LA METODOLOGÍA Y DEL INSTRUMENTO METODOLOGICO
_____________________________________________________________________________________
195
En la elección de cualquier instrumento de recogida de información, las investigaciones
deben sopesar las potencialidades y limitaciones de dichos instrumentos. Todos los
instrumentos tienen aspectos que se ajustan mejor a un tipo de problemática y son
deficientes en otra. Lo importante es la selección de los instrumentos que mejor cuadren
con el tipo de información que se desea reunir. Tales ventajas y dificultades deben estar
en relación además con los objetivos, recursos y población investigados242. Autores
como Sierra Bravo243 plantean que en dicha elección deben primar criterios sencillos y
claros:
• El grado de adecuación a las características del objeto de estudio de nuestra
investigación.
• El nivel de rigor y de calidad.
• La capacidad del personal participante en la investigación.
• El acceso a las fuentes de información necesarias.
• El tiempo.
• Los recursos disponibles
• Los costos humanos, sociales y económicos.
• Los aspectos éticos y morales
Todos los manuales de metodología de la investigación, unos más otros menos, llegan
finalmente a exponer un conjunto de métodos y técnicas de investigación. Por medio de
un proceso de operatividad, reducen los constructos, conceptos, ideas o hipótesis a
datos. La forma más general para caracterizar a las técnicas es con los procedimientos
de medida. Ellas intentan244:
• Obtener una medida de una característica observable, que la reduce a una
descripción numérica y transforma la característica en datos.
Gestión de la información
y registro de los datos
EN ESTE CAPÍTULO, APRENDEREMOS LO SIGUIENTE:
• Cómo abarca la gestión de la información los aspectos de la recopilación,
el control de calidad, el archivo y la accesibilidad a largo plazo a los datos
recogidos y sus metadatos asociados.
• La distinción entre datos, información, conocimientos y sabiduría.
• Qué mecanismo provoca que los proyecos de software arrojen tasas de fracaso
tan elevadas. Debatiremos sobre los factores y las teorías que contribuyen a
lograr buenos resultados.
• Un «ecosistema de conocimientos» propuesto como método de enfoque
o abordaje: el complejo sistema compuesto por personas, instituciones,
organizaciones, tecnologías y procesos, en el cual se genera, interpreta,
distribuye, absorbe, traduce y aprovecha el conocimiento.
4.2 Características estimadores
1) Sesgo. Se dice que un estimador es insesgado si la Media de la distribución del estimador es igual al parámetro.
Estimadores insesgados son la Media muestral (estimador de la Media de la población) y la Varianza (estimador de la Varianza de la población):
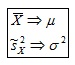
Ejemplo
En una población de 500 puntuaciones cuya Media (m) es igual a 5.09 han hecho un muestreo aleatorio (número de muestras= 10000, tamaño de las muestras= 100) y hallan que la Media de las Medias muestrales es igual a 5.09, (la media poblacional y la media de las medias muestrales coinciden). En cambio, la Mediana de la población es igual a 5 y la Media de las Medianas es igual a 5.1 esto es, hay diferencia ya que la Mediana es un estimador sesgado.
La Varianza es un estimador sesgado. Ejemplo: La Media de las Varianzas obtenidas con la Varianza
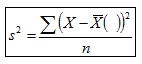
en un muestreo de 1000 muestras (n=25) en que la Varianza de la población es igual a 9.56 ha resultado igual a 9.12, esto es, no coinciden. En cambio, al utilizar la Cuasivarianza
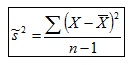
la Media de las Varianzas muestrales es igual a 9.5, esto es, coincide con la Varianza de la población ya que la Cuasivarianza es un estimador insesgado.
2) Consistencia. Un estimador es consistente si aproxima el valor del parámetro cuanto mayor es n (tamaño de la muestra).
Algunos estimadores consistentes son:
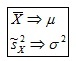
Ejemplo
En una población de 500 puntuaciones cuya Media (m) es igual a 4.9 han hecho tres muestreos aleatorios (número de muestras= 100) con los siguientes resultados:

vemos que el muestreo en que n=100 la Media de las Medias muestrales toma el mismo valor que la Media de la población.
3) Eficiencia. Diremos que un estimador es más eficiente que otro si la Varianza de la distribución muestral del estimador es menor a la del otro estimador. Cuanto menor es la eficiencia, menor es la confianza de que el estadístico obtenido en la muestra aproxime al parámetro poblacional.
Ejemplo
La Varianza de la distribución muestral de la Media en un muestreo aleatorio (número de muestras: 1000, n=25) ha resultado igual a 0.4. La Varianza de la distribución de Medianas ha resultado, en el mismo muestreo, igual a 1.12, (este resultado muestra que la Media es un estimador más eficiente que la Mediana).
Muestras preliminares de los proyectos aprobados en
La preparación de un proyecto de investigación requiere un trabajo sistemático que se irá perfilando en los sucesivos borradores del mismo.
El desarrollo del proyecto comienza con la idea general o particular sobre un determinado aspecto de la práctica clínica, diagnóstico, tratamiento, actuaciones, etc. La idea terminará de concretarse tras la revisión bibliográfica del tema, necesaria para situar el tema a investigar en el conocimiento actual
El proyecto de investigación definira los objetivos que pretende alcanzar. La definición clara de objetivos es el primer paso en la decisión del diseño a utilizar, las variables y el tipo de análisis. Hay que expresar el objetivo en términos generales, seguido de un objetivo específico donde se enuncie qué variables van a ser estudiadas, cómo van a cuantificarse y se especifique más la población de estudio.
Ningún estudio de investigación puede tener validez si previamente a la recogida de datos no se han especificado los objetivos.
La elaboracion del proyecto va a requerir tiempo y varias borradores y revisiones de los mismos. Únicamente un buen diseño carente de errores que intente responder a la pregunta de interés enunciada en el proyecto merecerá todo el esfuerzo ulterior de su puesta en marcha, recogida y análisis de resultados.
Los aspectos relacionados con los estudios de intervención en humanos requieren la aprobación de un comité de ensayos clínicos
ESTIMADOR:
Es un estadístico (es decir, es una función de la muestra) usado para estimar un parámetro desconocido de la población. Por ejemplo, si se desea conocer el precio medio de un artículo (el parámetro desconocido) se recogerán observaciones del precio de dicho artículo en diversos establecimientos (la muestra) y la media aritmética de las observaciones puede utilizarse como estimador del precio medio.
Para cada parámetro pueden existir varios estimadores diferentes. En general, escogeremos el estimador que posea mejores propiedades que los restantes, como insesgadez, eficiencia, convergencia y robustez (consistencia).
SESGO:
Se denomina sesgo de un estimador a la diferencia entre la esperanza (o valor esperado) del estimador y el verdadero valor del parámetro a estimar. Es deseable que un estimador sea insesgado o centrado, es decir, que su sesgo sea nulo por ser su esperanza igual al parámetro que se desea estimar.
Por ejemplo, si se desea estimar la media de una población, la media aritmética de la muestra es un estimador insesgado de la misma, ya que su esperanza (valor esperado) es igual a la media de la población.
EFICIENCIA:
Un estimador es más eficiente o preciso que otro, si la varianza del primero es menor que la del segundo.
CONVERGENCIA:
Para estudiar las características de un estimador no solo basta con saber el sesgo y la varianza, sino que además es útil hacer un análisis de su comportamiento y estabilidad en el largo plazo, esto es, su comportamiento asintótico. Cuando hablamos de estabilidad en largo plazo, se viene a la mente el concepto de convergencia. Luego, podemos construir sucesiones de estimadores y estudiar el fenómeno de la convergencia.
Comportamiento Asintótico: En el caso de las variables aleatorias, existen diversos tipos de convergencia, dentro de las cuales podemos distinguir:
-Convergencia en probabilidad (o débil).
-Convergencia casi segura (o fuerte).
-Convergencia en media cuadrática.
-Convergencia en distribución.
CONSISTENCIA:
También llamada robustez, se utilizan cuando no es posible emplear estimadores de mínima varianza, el requisito mínimo deseable para un estimador es que a medida que el tamaño de la muestra crece, el valor del estimador tiende a ser el valor del parámetro, propiedad que se denomina consistencia.



